CPU Cache
CPU Cache :在计算机存储系统的层次结构中,介于CPU和主存(Main Memory)之间的高速小容量存储器。
作用:CPU的运算速度比读写主存的速度快得多,这就使得CPU在访问主存时要花很长的等待时间,从而造成系统整体性能的下降。当CPU欲读取某个字节时,Cache会将主存中该字节所在的整个字块一次性调入,当CPU再次访问该字节所在字块的数据时,可直接从Cache中读取,极高地提高了数据的读取效率。当CPU需要访问的数据正好在Cache中时,称为Cache命中,若未命中时,则Cache需要重新从主存中将访问数据的整个字块读入。
Cache Line
Cache Line可以理解为CPU Cache中最小的缓存单位。当CPU需要访问主存中的某个数据时,会将其所在的Cache Line大小的数据全部读入Cache中。目前主流的CPU Cache的Cache Line大小都是 64Bytes。比如,如果你访问一个long数组,当数组中的一个值被加载到缓存中,它会额外加载另外7个。
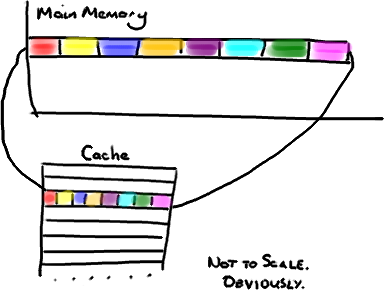
利用Cache Line的原理,我们可以非常快速的遍历数组中的数据。如果使用的数据结构在内存中不是物理上的相邻的话(链表),将得不到免费缓存加载所带来的优势。
可以测试一下,C语言中第一段代码将会比第二段代码的执行速度要快。
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
int num;
arr[i][j] = num;
}
}
for(int i = 0; i < n; i++) {
for(int j = 0; j < n; j++) {
int num;
arr[j][i] = num;
}
}
volatile 关键字
在多线程编程中,如果多个CPU核心访问了一个变量,那么在每个CPU核心的Cache中都会保存一个含有该变量的缓存行。volatile 关键字的作用就是避免编译器进行过度的优化,当该变量的值改变时都会写回到主存,并使其他CPU寄存器中包含该变量的缓存行无效,必须重新读取主存中包含该变量的值的缓存行。(请注意加粗内容,切记Cache的操作单位是缓存行!)
举个栗子:
class VolatileTest
{
public:
VolatileTest()
: _loop(true)
{}
void ThreadOne()
{
std::cout << "ThreadOne Start!" << std::endl;
while(_loop) {}
std::cout << "ThreadOne END!" << std::endl;
}
void ThreadTwo()
{
Poco::Thread::sleep(500);
std::cout << "ThreadTwo Start!" << std::endl;
_loop = false;
std::cout << "ThreadTwo END!" << std::endl;
}
private:
bool _loop;
};
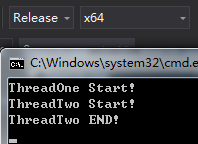
bool 类型的成员变量_loop初始值为treu,ThreadOne当_loop为true时阻塞。ThreadTwo等待500ms之后,将_loop的值改为false。在VS2015 Release模式下,ThreadOne并不会跳出循环:
但是,将_loop加上volatile关键字之后,同样在VS2015 Release模式下,ThreadOne就会正常地跳出循环:
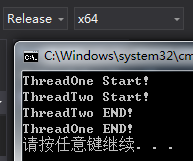
所以在多线程编程中,对于需要共享的变量最好在其声明之前加上volatile修饰符,以避免编译器的过度优化造成Bug。
伪共享
Cache Line的免费加载让CPU访问数据的效率得到了极大地提高,但是在多线程中,这也有一个弊端。
有这样一个情景,一个数组中有相邻元素head和tail,线程1需要访问并修改head元素,线程2需要访问并修改tail元素,看起来好像线程1和线程2毫无关系,但其实他们之间产生了非常影响性能的伪共享。
如下图所示,当线程1需要访问数组中的head元素,CPU Core1会将主存中其所在的缓存行加载到Cache中,这意味着Core1免费加载了tail元素。同理,线程二需要访问数组中的tail元素,Core2也同时加载了head元素。
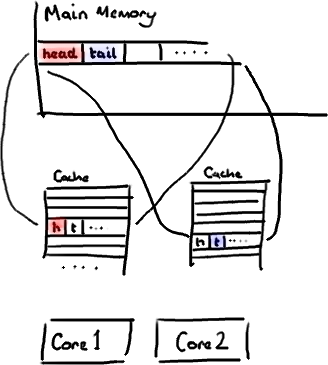
请注意,Cache的操作单位是整个缓存行。所以,当线程1更改了head的值时,会使其他所有存储head的缓存行都失效,因为其他缓存行中的head不是最新值了,当线程2想访问同一个缓存行中的tail时,Core2必须重新从主存中加载该缓存行。这就意味着,线程2被一个和它毫无关系的变量导致的Cache未命中给拖慢了。
这就是Cache免费加载带来的弊端——伪共享。伪共享的定义是多线程修改相互独立但处于同一个缓存行的变量时,某个线程的操作将会导致其他线程产生Cache未命中,从而互相影响彼此的性能。
缓存行填充
避免伪共享的一个解决办法就是 缓存行填充,在共享变量的前后填充空白数据使包含其的数据结构达到CPU的缓存行大小。例如:
struct CacheLinePaddingNumber
{
volatile std::atomic<int64_t> A;
int64_t a, b, c, d, e, f, g;
};
这样线程在访问A时,就不会发生伪共享而影响到其他线程的运行效率。
这里做一个简单的测试,证明伪共享对程序效率的影响。
struct CacheLinePaddingNumber
{
volatile std::atomic<int64_t> A;
int64_t a, b, c, d, e, f, g;
volatile std::atomic<int64_t> B;
int64_t h, i, j, k, l, m, n;
};
struct NormalNumber
{
volatile std::atomic<int64_t> A;
volatile std::atomic<int64_t> B;
};
CacheLinePaddingNumber 包含两个缓存行填充的int64原子类型的数据,NormalNumber 包含两个普通的int64原子类型的数据。
class NormalNumberTest
{
public:
NormalNumberTest()
{
data.A = 0;
data.B = 0;
}
void RunIncrese()
{
for (unsigned int i = 0; i < 10000000; ++i)
{
++data.A;
}
}
void RunDecrese()
{
for (unsigned int i = 0; i < 10000000; ++i)
{
--data.B;
}
}
private:
NormalNumber data;
};
class PaddingNumberTest
{
public:
PaddingNumberTest()
{
data.A = 0;
data.B = 0;
}
void RunIncrese()
{
for (unsigned int i = 0; i < 10000000; ++i)
{
++data.A;
}
}
void RunDecrese()
{
for (unsigned int i = 0; i < 10000000; ++i)
{
--data.B;
}
}
private:
CacheLinePaddingNumber data;
};
NormalNumberTest 和 PaddingNumberTest 都有两个线程,分别操作一千万此普通数和填充数中不相关的A和B,分别各自计算两个线程运行完毕所用的时间。在VS2015 Release模式测试结果如下:
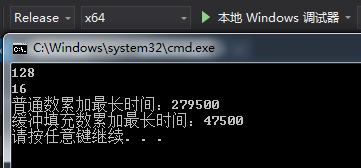
可以看出伪共享对性能的影响是非常大的。
参考资料:
http://cenalulu.github.io/linux/all-about-cpu-cache/
http://ifeve.com/disruptor-cacheline-padding/
http://ifeve.com/volatile/